Human Pose Estimation (HPE) is a critical problem in computer vision with applications in healthcare, sports, and human–computer interaction. As we noted in the MMPose study, the main challenges remain occlusion, variations in illumination, and complex body poses. Our objective has been to design and evaluate a deep learning approach that can handle these challenges and achieve higher accuracy in joint keypoint prediction compared to existing models.
Current State Summary
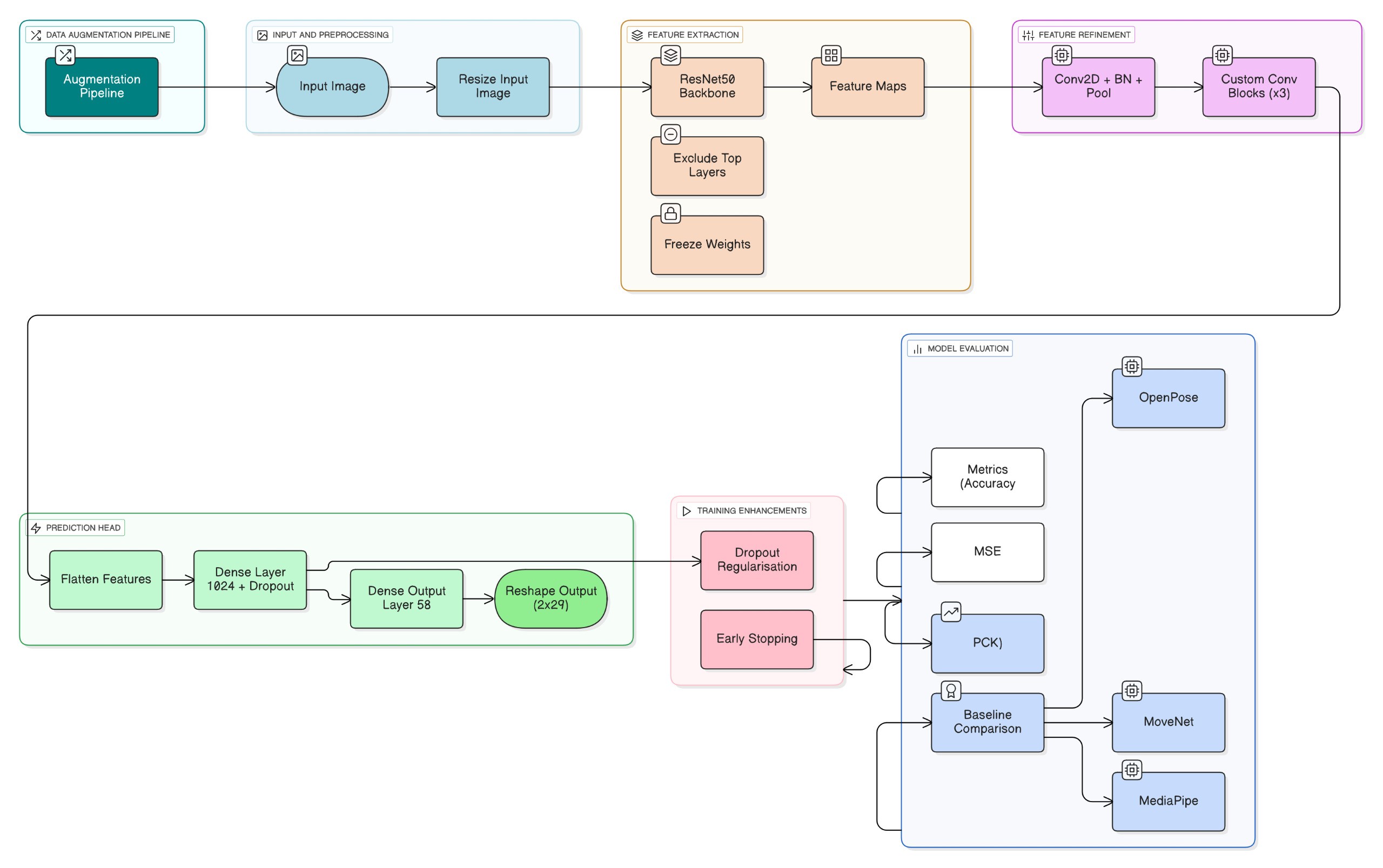
Our Methodology
We developed a CNN-based architecture for 2D human pose estimation:
-
Backbone – ResNet50
- Used as the feature extractor, pre-trained on ImageNet.
- Residual connections mitigate vanishing gradients and enable deep feature learning.
- Classification layers removed; convolutional layers initially frozen to retain generic features.
-
Custom Convolutional Layers
- Additional Conv2D + ReLU + Batch Normalisation + MaxPooling layers added.
- These adapt backbone features for the specific task of pose/keypoint prediction.
-
Dense and Output Layers
- Flattened features passed through dense layers with ReLU activation.
- Dropout (0.5) applied for regularisation.
- Final dense layer with
29 × 2neurons (for 29 keypoints, x and y coordinates). - Sigmoid activation ensures normalised outputs in [0, 1].
Dataset and Training
-
Dataset: FLIC (Frames Labeled in Cinema), 5,000 annotated frames. Covers diverse poses, occlusions, and backgrounds.
-
Augmentation: rotation (±30°), translation (20 %), shear (20 %), zoom (20 %), horizontal flip, brightness (0.8–1.2), and channel shift (±20). These augmentations reduced overfitting and improved generalisation.
-
Training setup:
- Loss function: Mean Squared Error (MSE).
- Optimizer: Adam (adaptive learning rate).
- Batch size: 32.
- Epochs: 15.
- Early stopping applied if validation loss stagnated for 10 epochs.
Performance Evaluation
We measured Accuracy, MSE, and PCK (Percentage of Correct Keypoints), and compared with state-of-the-art models.
| Model | Accuracy | MSE | PCK |
|---|---|---|---|
| Our Model | 0.9466 | 0.1288 | 0.8966 |
| MediaPipe | 0.8824 | 0.3000 | 0.8724 |
| MoveNet | 0.8325 | 0.2900 | 0.8279 |
| OpenPose | 0.4206 | 0.3300 | 0.4054 |
Observations:
- Our model consistently outperforms existing frameworks across all three metrics.
- Strong robustness observed under occlusion, extreme poses, and illumination changes.
- Predicted keypoints showed minimal error in both qualitative (visual) and quantitative comparisons.
MMPose 2D Pose Estimation – Technical Update
We reviewed the MMPose toolbox, an essential part of the OpenMMLab ecosystem, which provides state-of-the-art solutions for 2D human pose estimation. The repository represents significant progress in building accurate, efficient, and deployment-ready models :contentReference(Contributors, 2020).
Our analysis was structured around three main methodological paradigms: top-down, bottom-up, and emerging one-stage approaches.
Foundational Paradigms
-
Top-Down Approach (“Detect-then-Estimate”)
- First detects persons using an object detector, then applies a Single-Person Pose Estimator (SPPE) on each bounding box.
- High accuracy but inference cost scales with the number of persons.
- Recent integration with efficient detectors like RTMDet has reduced this limitation, making SPPE optimisation the main focus.
- MMPose benefits from direct integration with MMDetection, enabling flexible detector–pose estimator combinations.
-
Bottom-Up Approach (“Estimate-then-Group”)
- Processes the entire image in one pass, detecting all keypoints first, then grouping them into individuals.
- Runtime is independent of the number of people, making it suitable for dense crowds.
- The main drawback is the grouping stage, which can reduce accuracy in overlapping or crowded scenes.
-
One-Stage / Hybrid Models
- Newer approaches like YOLOX-Pose and RTMO merge detection and pose estimation into a single network.
- These eliminate pre-/post-processing and leverage innovations from object detection.
- Result: better balance between speed and accuracy compared to classical paradigms.
- Highlight: RTMO (“Real-Time One-Stage Multi-Person Pose Estimation”) integrates coordinate classification via dual 1-D heatmaps within a YOLO-based framework, achieving accuracy comparable to top-down methods while delivering significantly higher speed :contentReference(Contributors, 2020){index=1}.
Architectural Strategies
MMPose models primarily adopt two representation techniques:
-
Heatmap-Based Models
- Treat localisation as a dense prediction task.
- Predict heatmaps for each keypoint and extracts coordinates from peak activations.
- Examples: Simple Baselines (ResNet, ResNeXt, Swin), HRNet, Stacked Hourglass, Transformer-based models (ViTPose, HRFormer).
-
Coordinate Representation Models
- Designed for faster inference by avoiding high-resolution heatmaps.
- Early approach: Direct Regression (DeepPose).
- Modern approach: SimCC, which splits localisation into two lightweight 1D classification problems (x and y).
- Significantly improves speed with limited accuracy loss.
Key Models and Innovations
-
RTMPose
- Efficient top-down model combining CSPNeXt backbone with SimCC head.
- Optimised for speed–accuracy trade-off, demonstrating that top-down methods can be accurate and real-time :contentReference(Jiang et al., 2023){index=2}.
-
RTMO
- A one-stage model integrating coordinate classification into a YOLO-based framework.
- Achieves accuracy comparable to strong top-down methods while maintaining single-pass inference speed :contentReference(Lu et al., 2023){index=3}.
-
HRNet
- Maintains parallel high-resolution representations across the network.
- Strong choice for tasks requiring high spatial precision.
Performance and Model Selection
Benchmarks using AP on COCO, GFLOPs/parameters, and FPS indicate that models like RTMPose lie on the Pareto frontier, offering maximum accuracy given computational constraints.
Deployment recommendations:
- Maximum Accuracy: ViTPose-H/L, HRNet-W48.
- Real-Time (Desktop/Server): RTMPose-m/l with TensorRT or ONNX Runtime.
- Edge/Mobile Devices: RTMPose-s/t, Lite-HRNet, MobileNetV2.
- Crowded Scenes: RTMO or DEKR due to constant-time inference, though efficient top-down models remain competitive.
Conclusion
Our analysis indicates that the classical “top-down = accurate, bottom-up = fast” trade-off is now outdated. Innovations such as RTMPose and RTMO demonstrate that models can achieve both high accuracy and efficiency, while being suitable for deployment across diverse environments (mobile to server).
The ongoing research trend is towards models that are accurate, lightweight, robust, and scalable, bridging the gap between research performance and real-world applicability.